
GoogleサーチコンソールのCLS指標が精度が高まるように更新されたというアナウンスされた。
多くのページは良い方向にCLSの値が変わるということのようだ。本ブログでは前回4/8のCLS検証終了後、良好ページが175→191, 要改善がまた発生していて0→28というのが現状。(アナウンスされている更新が適用されたかどうかは不明)
ところで、CLSの改善が影響しているかどうかわからないが、検索パフォーマンスが例えば表示では先週の平日3000程度から今週は4500程度まで増えている。
GoogleサーチコンソールのCLS指標が精度が高まるように更新されたというアナウンスされた。
多くのページは良い方向にCLSの値が変わるということのようだ。本ブログでは前回4/8のCLS検証終了後、良好ページが175→191, 要改善がまた発生していて0→28というのが現状。(アナウンスされている更新が適用されたかどうかは不明)
ところで、CLSの改善が影響しているかどうかわからないが、検索パフォーマンスが例えば表示では先週の平日3000程度から今週は4500程度まで増えている。
前回のデータのガウシアンフィッティングを応用した複数のガウシアンにフィッティングする方法について今回は紹介する。異なる吸収特性をもつものが重なった場合、複数の特徴(吸収量a、吸収中心b、吸収幅c)をもつガウシアンを用いてフィッティングすることで、それぞれの特徴量に分解することができる。
なおコード自体は
研究者のための実践データ処理~Pythonでピークフィッティング~ - Qiita
を参考にしている。
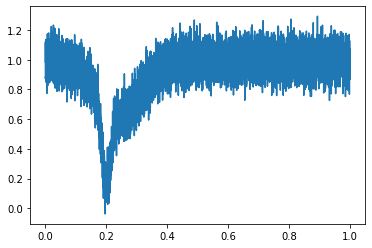
前回と同様に仮想的な2つのガウシアンを含む透過データを生成する。真値をガウシアンのパラメータとしてa=0.5, b=0.2, c=0.02, 2つ目のパラメータはa2=0.4, b2=0.24, c2=0.10,として、透過の平均を1、そこに正規分布乱数を加えたものを仮想データとする。
import numpy as np import matplotlib.pyplot as plt from scipy.optimize import curve_fit a=0.5 b=200e-3 c=20e-3 a2=0.4 b2=240e-3 c2=100e-3 y2=1-a*np.exp(-1*(x-b)**2/c**2)-a2*np.exp(-1*(x-b2)**2/c2**2)+0.08*np.random.normal(size=np.size(x)) plt.plot(x,y2)
幅の広いガウシアン(c2=0.1)の効果でガウシアンの裾が片側だけ広がったようなデータになっている。
フィッティングに使用する複数のガウシアンはfor文とlistを用いて定義する。
def func(x, *params): #paramsの長さでフィッティングする関数の数を判別。 num_func = int(len(params)/3) #ガウス関数にそれぞれのパラメータを挿入してy_listに追加。 y_list = [] for i in range(num_func): y = np.zeros_like(x) param_range = list(range(3*i,3*(i+1),1)) amp = params[int(param_range[0])] ctr = params[int(param_range[1])] wid = params[int(param_range[2])] y = y + amp * np.exp( -((x - ctr)/wid)**2) y_list.append(y) #y_listに入っているすべてのガウス関数を重ね合わせる。 y_sum = np.zeros_like(x) for i in y_list: y_sum = y_sum + i #最後にバックグラウンドを追加。 y_sum = y_sum + params[-1] return y_sum
初期値のリストを以下のように作成する。
#初期値のリストを作成 #[amp,ctr,wid] guess = [] guess_x=0.2 guess.append([-0.8,guess_x , 0.03]) guess.append([-0.3,guess_x , 0.03]) #バックグラウンドの初期値 background = np.mean(y) #初期値リストの結合 guess_total = [] for i in guess: guess_total.extend(i) guess_total.append(background)
関数へのフィッティングは前回同様scipy.optimizeからcurve_fitをロードして'curve_fit`を実行する
from scipy.optimize import curve_fit popt, pcov = curve_fit(func2, x, y, p0=guess_total) popt array([-0.39329994, 0.24159909, 0.10034837, -0.50784074, 0.19993044, -0.0202291 , 0.99990966])
poptがフィッティングされた各パラメータだが、3つで1組のガウシアンで今回は2組あり、最後はバイアスになる。
1組目は[-0.39329994, 0.24159909, 0.10034837]だが幅の広いガウシアン[a2,b2,c2]=[-0.4,0.25,0.1]と一致する。また [-0.50784074, 0.19993044, -0.0202291]は幅の狭いガウシアン [a,b,c]=[-0.5,0.2,0.01]
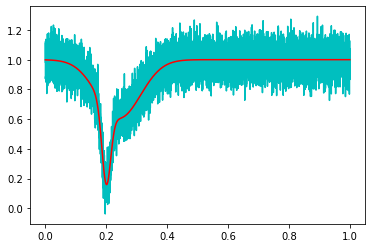
と一致する。元データと2つのガウシアンを重ね合わせてみると、よく合っていることがわかる。
fit = func2(x, *popt) plt.plot(x,y,'c') plt.plot(x,fit,'r')
今回はデータのガウシアンフィッティングについて紹介する。分光などのスペクトルを扱うデータでは吸収あるいは透過データの中から、変化量や変化幅をフィッティングにより求めるケースがある。 フィッティングに用いる関数の1つとしてガウシアンフィッティングのパラメータから、吸収量a・吸収中心b・吸収線幅cを求める。
なおコード自体は
研究者のための実践データ処理~Pythonでピークフィッティング~ - Qiita
を参考にしている。
今回は透過データの中から吸収の特徴(吸収量a・吸収中心b・吸収線幅c)を想定して、仮想的な透過データを生成する。 真値をガウシアンのパラメータとしてa=0.5, b=0.2, c=0.02として、透過の平均を1、そこに正規分布乱数を加えたものを仮想データとして、仮想データに対してガウシアンフィッティングして真値のパラメータと比較する。
import numpy as np import matplotlib.pyplot as plt x=np.linspace(0, 1, 10000) a=0.5 b=200e-3 c=20e-3 y=1-a*np.exp(-1*(x-b)**2/c**2)+0.08*np.random.normal(size=np.size(x)) plt.plot(x,y)

フィッティングパラメータは[a,b,c, bias]という4要素を想定して、フィッティングに使用するガウシアンを関数として定義する。以下関数func2(x,*params)では
を返す関数で、パラメータリストparamsを変化させて元データに対してフィッティングを行う。
def func2(x, *params): y = np.zeros_like(x) amp=params[0] ctr =params[1] wid = params[2] y = amp * np.exp( -((x - ctr)/wid)**2) y_sum = y + params[-1] return y_sum
初期値のリストを以下のように作成する。
#初期値のリストを作成 #[a,b,c] guess = [] guess.append([-0.8,0.21 , 0.05]) #真値と少しずらす #バックグラウンドの初期値 bias = np.mean(y) #データ平均値を使用 #初期値リストの結合 guess_total = [] for i in guess: guess_total.extend(i) guess_total.append(bias) #初期値リスト名
関数へのフィッティングはscipy.optimizeからcurve_fitをロードする。
curv_fit(func,x,y,params)はfuncがフィッティングする関数('func2()`), x,yはフィッティングするデータ, paramsは初期値のリストを用いる。
以下1行でガウシアンフィッティングが実行できる。
from scipy.optimize import curve_fit popt, pcov = curve_fit(func2, x, y, p0=guess_total) popt >array([-0.50129349, 0.20001395, 0.01949098, 0.99814112])
poptがフィッティングされた各パラメータだが、真値:[-0.5,0.2,0.02,1]に対してほぼ一致しているといえる。
さらにフィッティングで得られたパラメータを用いて元データとガウシアンを重ね合わせてみると、よく合っていることがわかる。
fit = func2(x, *popt) plt.plot(x,y,'c') plt.plot(x,fit,'r')

次に初期値の値を少しずらしa,b,cの組み合わせを[-0.8,0.3, 0.05]でフィッティングすると真値から大きくずれてしまうことがわかる。
popt, pcov = curve_fit(func2, x, y, p0=guess_total) popt >array([0.06021785, 0.71914563, 0.37638693, 0.946643 ])
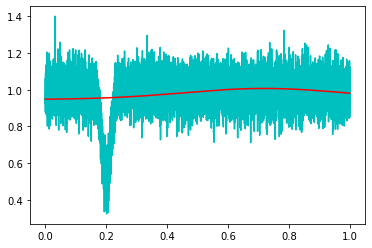
他のパラメータは多少離れていてもフィッティングできるが、bに関してはシビアのようだ。対策としては生データから最小値のインデックスをnp.argminで取得してbの初期値をx[np.argmin(y)]としておくとガウシアンのピーク付近を初期値に設定できる。