Pythonによるデータ処理2 ~ ガウシアンフィッティング
今回はデータのガウシアンフィッティングについて紹介する。分光などのスペクトルを扱うデータでは吸収あるいは透過データの中から、変化量や変化幅をフィッティングにより求めるケースがある。 フィッティングに用いる関数の1つとしてガウシアンフィッティングのパラメータから、吸収量a・吸収中心b・吸収線幅cを求める。
なおコード自体は
研究者のための実践データ処理~Pythonでピークフィッティング~ - Qiita
を参考にしている。
今回は透過データの中から吸収の特徴(吸収量a・吸収中心b・吸収線幅c)を想定して、仮想的な透過データを生成する。 真値をガウシアンのパラメータとしてa=0.5, b=0.2, c=0.02として、透過の平均を1、そこに正規分布乱数を加えたものを仮想データとして、仮想データに対してガウシアンフィッティングして真値のパラメータと比較する。
import numpy as np import matplotlib.pyplot as plt x=np.linspace(0, 1, 10000) a=0.5 b=200e-3 c=20e-3 y=1-a*np.exp(-1*(x-b)**2/c**2)+0.08*np.random.normal(size=np.size(x)) plt.plot(x,y)

フィッティングパラメータは[a,b,c, bias]という4要素を想定して、フィッティングに使用するガウシアンを関数として定義する。以下関数func2(x,*params)では
を返す関数で、パラメータリストparamsを変化させて元データに対してフィッティングを行う。
def func2(x, *params): y = np.zeros_like(x) amp=params[0] ctr =params[1] wid = params[2] y = amp * np.exp( -((x - ctr)/wid)**2) y_sum = y + params[-1] return y_sum
初期値のリストを以下のように作成する。
#初期値のリストを作成 #[a,b,c] guess = [] guess.append([-0.8,0.21 , 0.05]) #真値と少しずらす #バックグラウンドの初期値 bias = np.mean(y) #データ平均値を使用 #初期値リストの結合 guess_total = [] for i in guess: guess_total.extend(i) guess_total.append(bias) #初期値リスト名
関数へのフィッティングはscipy.optimizeからcurve_fitをロードする。
curv_fit(func,x,y,params)はfuncがフィッティングする関数('func2()`), x,yはフィッティングするデータ, paramsは初期値のリストを用いる。
以下1行でガウシアンフィッティングが実行できる。
from scipy.optimize import curve_fit popt, pcov = curve_fit(func2, x, y, p0=guess_total) popt >array([-0.50129349, 0.20001395, 0.01949098, 0.99814112])
poptがフィッティングされた各パラメータだが、真値:[-0.5,0.2,0.02,1]に対してほぼ一致しているといえる。
さらにフィッティングで得られたパラメータを用いて元データとガウシアンを重ね合わせてみると、よく合っていることがわかる。
fit = func2(x, *popt) plt.plot(x,y,'c') plt.plot(x,fit,'r')

次に初期値の値を少しずらしa,b,cの組み合わせを[-0.8,0.3, 0.05]でフィッティングすると真値から大きくずれてしまうことがわかる。
popt, pcov = curve_fit(func2, x, y, p0=guess_total) popt >array([0.06021785, 0.71914563, 0.37638693, 0.946643 ])
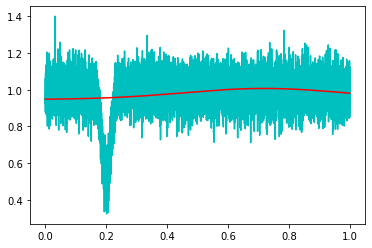
他のパラメータは多少離れていてもフィッティングできるが、bに関してはシビアのようだ。対策としては生データから最小値のインデックスをnp.argminで取得してbの初期値をx[np.argmin(y)]としておくとガウシアンのピーク付近を初期値に設定できる。